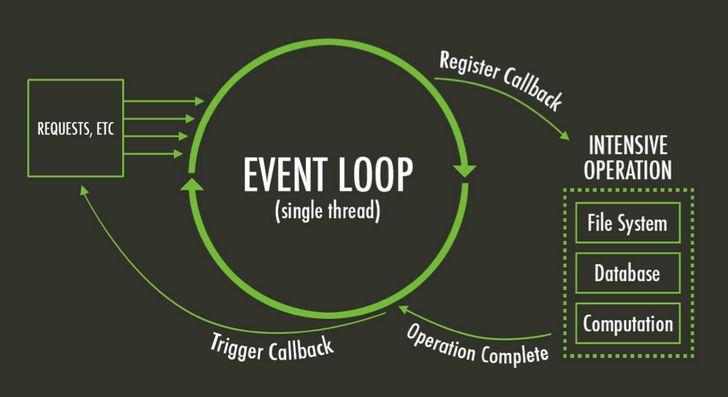
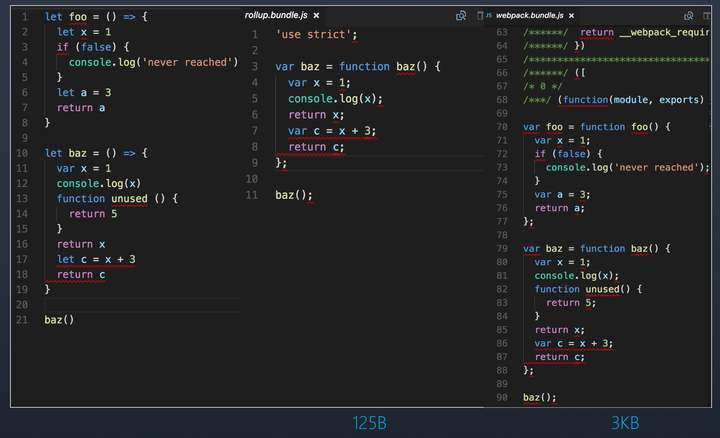
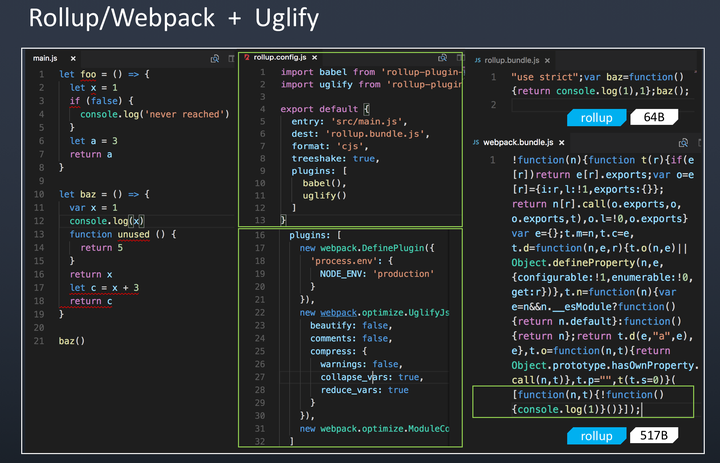
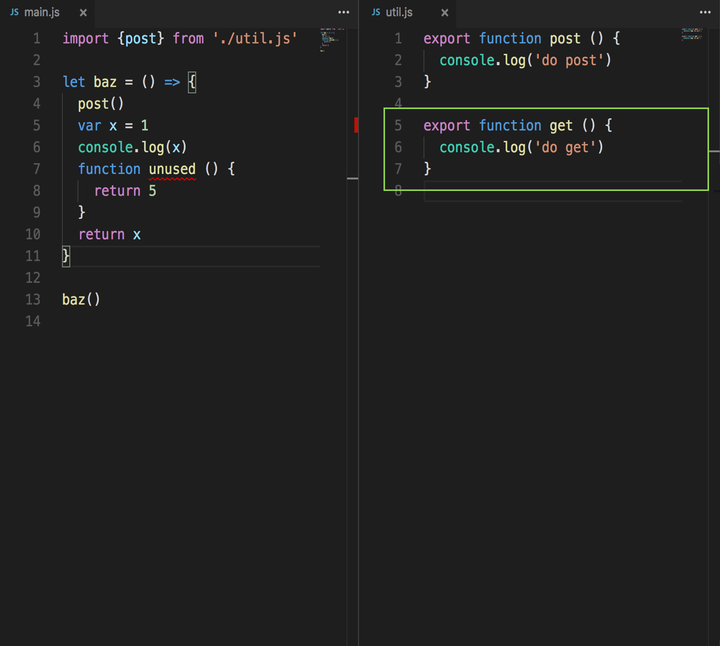
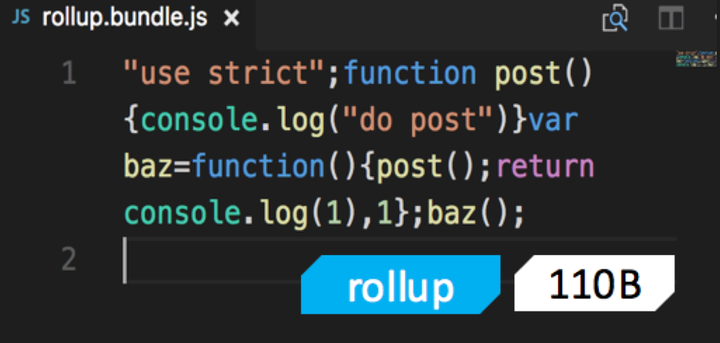
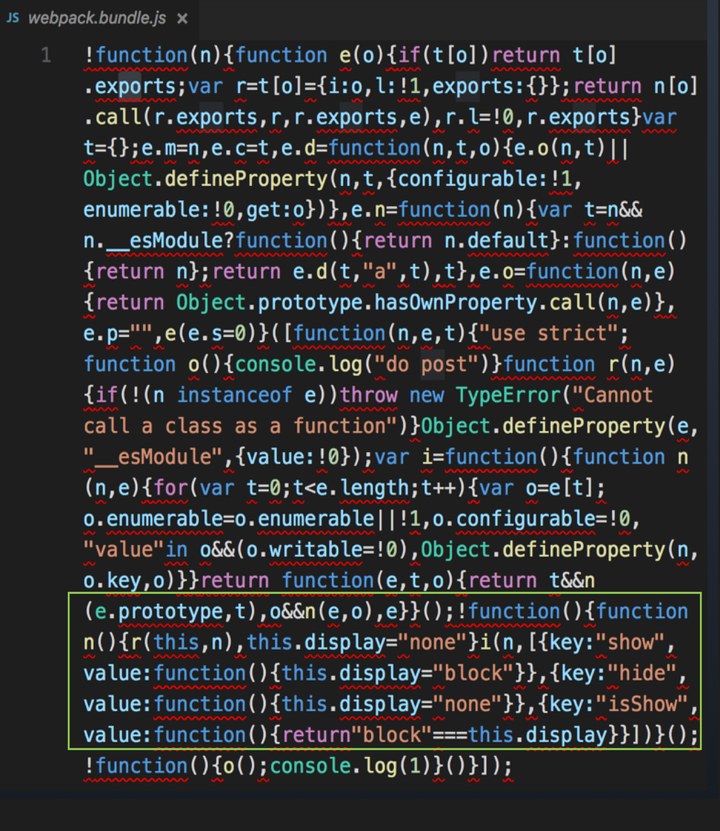
// 创建工作进程 let workers = [] let cur = 0 for (let i = 0; i < cpuNum; ++i) { workers.push(childProcess.fork('./worker.js')) console.log('Create worker-' + workers[i].pid) }
// 创建工作进程 let workers = [] let cur = 0 for (let i = 0; i < cpuNum; ++i) { workers.push(childProcess.fork('./worker.js')) console.log('Create worker-' + workers[i].pid) }
// 创建TCP服务器 const server = net.createServer()
server.listen(8080, () => { console.log('TCP server: 127.0.0.1:8080') // 监听端口后将服务器句柄发送给工作进程 for (let i = 0; i < cpuNum; ++i) { workers[i].send('server', server) } // 关闭主线程服务器的端口监听 server.close() })
// 创建工作进程 let workers = [] let cur = 0 for (let i = 0; i < cpuNum; ++i) { workers.push(childProcess.fork('./worker.js')) console.log('Create worker-' + workers[i].pid) }
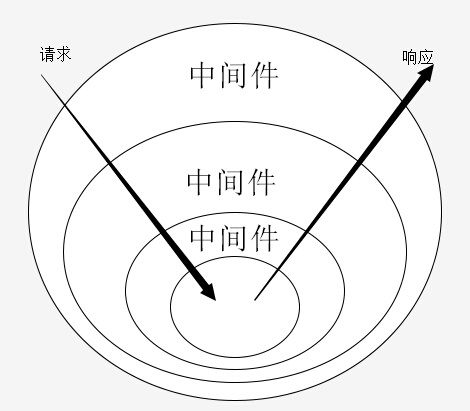
use(fn) { if (typeof fn !== 'function') throw new TypeError('middleware must be a function!'); if (isGeneratorFunction(fn)) { deprecate('Support for generators will be removed in v3. ' + 'See the documentation for examples of how to convert old middleware ' + 'https://github.com/koajs/koa/blob/master/docs/migration.md'); fn = convert(fn); } debug('use %s', fn._name || fn.name || '-'); this.middleware.push(fn); return this; }
function compose (middleware) { return function (context, next) { // last called middleware # let index = -1 return dispatch(0)
function dispatch (i) { if (i <= index) return Promise.reject(new Error('next() called multiple times')) index = i let fn = middleware[i] if (i === middleware.length) fn = next if (!fn) return Promise.resolve() try { return Promise.resolve(fn(context, function next () { return dispatch(i + 1) })) } catch (err) { return Promise.reject(err) } } } }
二、一个 n 个大小写字母组成的字符串按 ascii 码从小到大排序 查找字符串中第 k 个最小 ascii 码的字母输出该字母所在字符串位置索引
1 2 3 4 5 6
function lookup(str,key){ if(typeof str !='string'||key<1)return -1; let value = str.split("").sort()[key-1]; return str.indexOf(value); } console.log(lookup('asasdskdjdfgnsdkfnmsASDdf',5)+1)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
let getIndexChar = (str,index)=>{ let sortChar = [] for(let i=0;i<str.length;i++) { sortChar.push(str.charCodeAt(i)) } sortChar = sortChar.sort((a,b)=>{ return a-b })
let indexCode = -1 for(let i=0;i<str.length;i++) { if(str[i].charCodeAt(0)==sortChar[index]) { indexCode = i } }
return indexCode } getIndexChar('asdEQW',1) //4
三、ts 工具函数
1、实现一个 ts 的工具函数 GetOnlyFnProps ,提取泛型类型 T 中字段类型是函数的工具函数,其中 T 属于一个对象。
1 2 3 4 5 6 7
type GetOnlyFnKeys<T extends object> = { [Key in keyof T]: T[K] extends Function ? K : never }
type GetOnlyFnProps<T extends object> = { [K in GetOnlyFnKeys<T>]: T[K] }
实现一个 ts 的工具函数 UnGenericPromise ,提取 Promise 中的泛型类型
1
type UnGenericPromise<T extends Promise<any>> = T extends Promise<infer U> ? U : never
import { Button, Col, message as Message, Row, Icon } from 'antd' import { Link } from 'react-router-dom' import React from 'react' import MessageListFilter, { IMessageListFilter } from './components/MessageListFilter' import MessageListTable from './components/MessageListTable' import MessageService from '../../../service/driverManage/MessageService'
IndexPage has a method called shouldComponentUpdate(). shouldComponentUpdate should not be used when extending React.PureComponent. Please extend React.Component if shouldComponentUpdate is used.
import React from "react"; import ReactDOM from "react-dom"; import "./index.css"; import * as serviceWorker from "./serviceWorker"; import { BrowserRouter as Router, Route } from "react-router-dom";
import { createBrowserHistory } from "history"; import loadable from './utils/loadable'