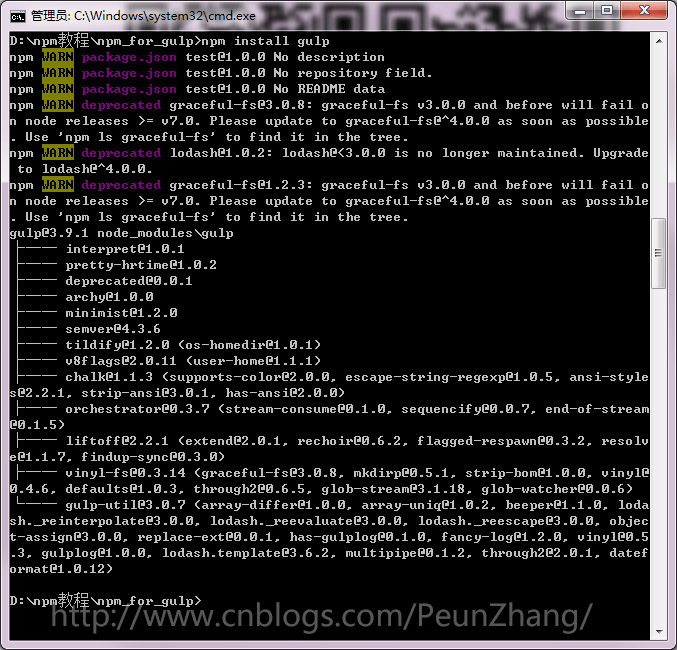
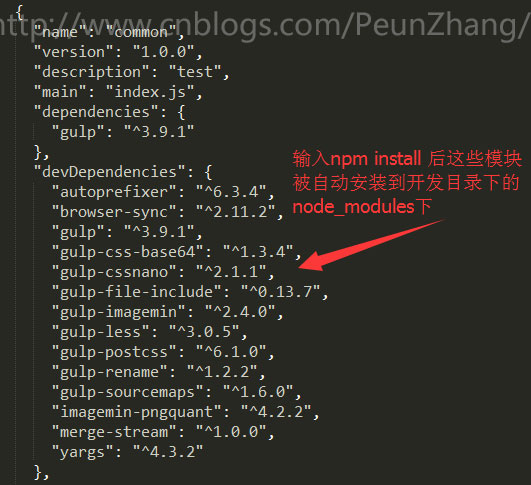
该命令写在 package.json 文件 scripts 的 test 字段中,可以自定义该命令来执行一些操作,如
1 2 3
"scripts": { "test": "gulp release" },
此时在 cmd 中输入 npm test 命令相当于执行 gulpfile.js 文件自定义的 release 命令。
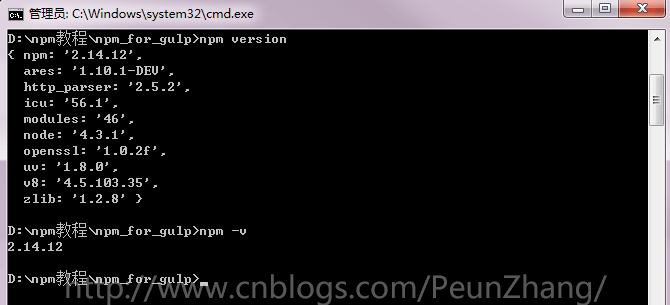
15. npm version 查看模块版本
基础语法
1 2 3 4 5
npm version [<newversion> | major | minor | patch | premajor | preminor | prepatch | prerelease | from-git]
'npm [-v | --version]' to print npm version 'npm view <pkg> version' to view a package's published version 'npm ls' to inspect current package/dependency versions
vi 命令是 UNIX 操作系统和类 UNIX 操作系统中最通用的全屏幕纯文本编辑器。Linux 中的 vi 编辑器叫 vim,它是 vi 的增强版(vi Improved),与 vi 编辑器完全兼容,而且实现了很多增强功能。
进入 vi 的命令
1 2 3 4 5
vi filename :打开或新建文件,并将光标置于第一行首 vi n filename :打开文件,并将光标置于第n行首 vi /pattern filename:打开文件,并将光标置于第一个与pattern匹配的串处 vi -r filename :在上次正用vi编辑时发生系统崩溃,恢复filename vi filename....filename :打开多个文件,依次进行编辑
man 命令用来查询和解释一个命令的使用方法和这个命令的注意事项。这个查询在每个 Linux 上都有。通常,使用者只要输入命令 man 和这个命令的名称 shell 就会列出一份完整的说明。标准用法:
man 命令的名称
要查询 ls 命令的说明书页,输入命令:
man ls
要翻阅说明书页,可以使用 Page Up 和 Page Down 键,或使用空格键向后翻一页,使用 b 向前翻。要退出说明书页,输入命令 q。要在说明书页中搜索关键字,输入命令/和要搜索的关键字或短语,然后按 Enter 键即可。所有出现在说明书页中的关键字都会被突出显示,允许快速地阅读上下文中的关键字。
6.2 locate 命令
locate 命令的主要功能是定位文件和目录。有时候,只知道某一文件或目录存在,却不知道在哪儿,就可以用 locate 来定位文件和目录。使用 locate 命令,将会看到每一个包括搜索中间的文件和目录。例如,如果想要搜索带有 test 的这个词的文件,输入命令:
db.users.update({age: 25}, {$set: {name: 'changeName'}}, false, true); 相当于:update users set name = ‘changeName' where age = 25; db.users.update({name: 'Lisi'}, {$inc: {age: 50}}, false, true); 相当于:update users set age = age + 50 where name = ‘Lisi'; db.users.update({name: 'Lisi'}, {$inc: {age: 50}, $set: {name: 'hoho'}}, false, true); 相当于:update users set age = age + 50, name = ‘hoho' where name = ‘Lisi';
show dbs:显示数据库列表 show collections:显示当前数据库中的集合(类似关系数据库中的表) show users:显示用户 use <db name>:切换当前数据库,这和MS-SQL里面的意思一样 db.help():显示数据库操作命令,里面有很多的命令 db.foo.help():显示集合操作命令,同样有很多的命令,foo指的是当前数据库下,一个叫foo的集合,并非真正意义上的命令 db.foo.find():对于当前数据库中的foo集合进行数据查找(由于没有条件,会列出所有数据) db.foo.find( { a : 1 } ):对于当前数据库中的foo集合进行查找,条件是数据中有一个属性叫a,且a的值为1
string set name cxx get name getrange name 0 -1 字符串分段 getset name new_cxx 设置值,返回旧值 mset key1 key2 批量设置 mget key1 key2 批量获取 setnx key value 不存在就插入(not exists) setex key time value 过期时间(expire) setrange key index value 从index开始替换value incr age 递增 incrby age 10 递增 decr age 递减 decrby age 10 递减 incrbyfloat 增减浮点数 append 追加 strlen 长度 getbit/setbit/bitcount/bitop 位操作
hash hset myhash name cxx hget myhash name hmset myhash name cxx age 25 note "i am notes" hmget myhash name age note hgetall myhash 获取所有的 hexists myhash name 是否存在 hsetnx myhash score 100 设置不存在的 hincrby myhash id 1 递增 hdel myhash name 删除 hkeys myhash 只取key hvals myhash 只取value hlen myhash 长度
list lpush mylist a b c 左插入 rpush mylist x y z 右插入 lrange mylist 0 -1 数据集合 lpop mylist 弹出元素 rpop mylist 弹出元素 llen mylist 长度 lrem mylist count value 删除 lindex mylist 2 指定索引的值 lset mylist 2 n 索引设值 ltrim mylist 0 4 删除key linsert mylist before a 插入 linsert mylist after a 插入 rpoplpush list list2 转移列表的数据
排序: sort mylist 排序 sort mylist alpha desc limit 0 2 字母排序 sort list by it:* desc by命令 sort list by it:* desc get it:* get参数 sort list by it:* desc get it:* store sorc:result sort命令之store参数:表示把sort查询的结果集保存起来
grant select,insert,update,delete on *.* to [email=test1@”%]test1@”%[/email]” Identified by “abc”;
但增加的用户是十分危险的,你想如某个人知道 test1 的密码,那么他就可以在 internet 上的任何一台电脑上登录你的 mysql 数据库并对你的数据可以为所欲为了,解决办法见 2。
2、增加一个用户 test2 密码为 abc,让他只可以在 localhost 上登录,并可以对数据库 mydb 进行查询、插入、修改、删除的操作(localhost 指本地主机,即 MYSQL 数据库所在的那台主机),这样用户即使用知道 test2 的密码,他也无法从 internet 上直接访问数据库,只能通过 MYSQL 主机上的 web 页来访问了。
grant select,insert,update,delete on mydb.* to [email=test2@localhost]test2@localhost[/email] identified by “abc”;
如果你不想 test2 有密码,可以再打一个命令将密码消掉。
grant select,insert,update,delete on mydb.* to [email=test2@localhost]test2@localhost[/email] identified by “”;
mysql> drop database if exists drop_database;//if exists 判断数据库是否存在,不存在也不产生错误 Query OK, 0 rows affected (0.00 sec)
4.4 连接数据库
命令: use <数据库名>
例如:如果 xhkdb 数据库存在,尝试存取它: mysql> use xhkdb; 屏幕提示:Database changed
use 语句可以通告 MySQL 把 db_name 数据库作为默认(当前)数据库使用,用于后续语句。 该数据库保持为默认数据库,直到语段的结尾,或者直到发布一个不同的 USE 语句:
1 2 3 4
mysql> USE db1; mysql> SELECT COUNT(*) FROM mytable; # selects from db1.mytable mysql> USE db2; mysql> SELECT COUNT(*) FROM mytable; # selects from db2.mytable
使用 USE 语句为一个特定的当前的数据库做标记,不会阻碍您访问其它数据库中的表。下面的例子可以从 db1 数据库访问作者表,并从 db2 数据库访问编辑表:
1 2 3
mysql> USE db1; mysql> SELECT author_name,editor_name FROM author,db2.editor -> WHERE author.editor_id = db2.editor.editor_id;
USE 语句被设立出来,用于与 Sybase 相兼容。
有些网友问到,连接以后怎么退出。其实,不用退出来,use 数据库后,使用 show databases 就能查询所有数据库,如果想跳到其他数据库,用 use 其他数据库名字 就可以了。
3. 显示年月日 SELECT DAYOFMONTH(CURRENT_DATE); +--------------------------+ | DAYOFMONTH(CURRENT_DATE) | +--------------------------+ | 15 | +--------------------------+ 1 row in set (0.01 sec)
SELECT MONTH(CURRENT_DATE); +---------------------+ | MONTH(CURRENT_DATE) | +---------------------+ | 9 | +---------------------+ 1 row in set (0.00 sec)
SELECT YEAR(CURRENT_DATE); +--------------------+ | YEAR(CURRENT_DATE) | +--------------------+ | 2009 | +--------------------+ 1 row in set (0.00 sec)
4. 显示字符串 mysql> SELECT "welecome to my blog!"; +----------------------+ | welecome to my blog! | +----------------------+ | welecome to my blog! | +----------------------+ 1 row in set (0.00 sec)
6. 串接字符串 select CONCAT(f_name, " ", l_name) AS Name from employee_data where title = 'Marketing Executive'; +---------------+ | Name | +---------------+ | Monica Sehgal | | Hal Simlai | | Joseph Irvine | +---------------+ 3 rows in set (0.00 sec) 注意:这里用到CONCAT()函数,用来把字符串串接起来。另外,我们还用到以前学到的AS给结果列'CONCAT(f_name, " ", l_name)'起了个假名。
mysql> create table MyClass( > id int(4) not null primary key auto_increment, > name char(20) not null, > sex int(4) not null default '0', > degree double(16,2));
5.2 删除数据表
命令:drop table <表名>
例如:删除表名为 MyClass 的表
mysql> drop table MyClass;
DROP TABLE 用于取消一个或多个表。您必须有每个表的 DROP 权限。所有的表数据和表定义会被取消,所以使用本语句要小心!
drop database if exists school; //如果存在SCHOOL则删除 create database school; //建立库SCHOOL use school; //打开库SCHOOL create table teacher //建立表TEACHER ( id int(3) auto_increment not null primary key, name char(10) not null, address varchar(50) default ‘深圳’, year date ); //建表结束
//以下为插入字段 insert into teacher values(”,’allen’,'大连一中’,'1976-10-10′); insert into teacher values(”,’jack’,'大连二中’,'1975-12-23′);
如果你在mysql提示符键入上面的命令也可以,但不方便调试。 1、你可以将以上命令原样写入一个文本文件中,假设为school.sql,然后复制到c:\\下,并在DOS状态进入目录[url=file://\\mysql\\bin]\\mysql\\bin[/url],然后键入以下命令: mysql -uroot -p密码 < c:\\school.sql 如果成功,空出一行无任何显示;如有错误,会有提示。(以上命令已经调试,你只要将//的注释去掉即可使用)。
drop database if exists school; //如果存在SCHOOL则删除 create database school; //建立库SCHOOL use school; //打开库SCHOOL create table teacher //建立表TEACHER ( id int(3) auto_increment not null primary key, name char(10) not null, address varchar(50) default ''深圳'', year date ); //建表结束
//以下为插入字段 insert into teacher values('''',''glchengang'',''深圳一中'',''1976-10-10''); insert into teacher values('''',''jack'',''深圳一中'',''1975-12-23'');
注:在建表中
1、将 ID 设为长度为 3 的数字字段:int(3);并让它每个记录自动加一:auto_increment;并不能为空:not null;而且让他成为主字段 primary key。
2、将 NAME 设为长度为 10 的字符字段
3、将 ADDRESS 设为长度 50 的字符字段,而且缺省值为深圳。
4、将 YEAR 设为日期字段。
8、Mysql 语句记录
1 2 3
use mysql; set password for 'root'@'localhost'=password('123456'); flush privileges;
import React from 'react'; import { routerRedux, Route ,Switch} from 'dva/router'; import { LocaleProvider } from 'antd'; import App from '../components/App/App'; import Flex from '../components/Header/index'; import Login from '../pages/Login/Login'; import Home from '../pages/Home/Home'; import zhCN from 'antd/lib/locale-provider/zh_CN'; const {ConnectedRouter} = routerRedux;
import Model from 'dva-model'; // import effect from 'dva-model/effect'; import queryString from 'query-string'; import pathToRegexp from 'path-to-regexp'; import {ManagementPage as namespace} from '../../utils/namespace'; import { getPages, } from '../../services/page';