一. 什么是 Tree-shaking

先来看一下 Tree-shaking 原始的本意
上图形象的解释了 Tree-shaking 的本意,本文所说的前端中的 tree-shaking 可以理解为通过工具”摇”我们的 JS 文件,将其中用不到的代码”摇”掉,是一个性能优化的范畴。具体来说,在 webpack 项目中,有一个入口文件,相当于一棵树的主干,入口文件有很多依赖的模块,相当于树枝。实际情况中,虽然依赖了某个模块,但其实只使用其中的某些功能。通过 tree-shaking,将没有使用的模块摇掉,这样来达到删除无用代码的目的。

Tree-shaking 较早由 Rich_Harris 的 rollup 实现,后来,webpack2 也增加了 tree-shaking 的功能。其实在更早,google closure compiler 也做过类似的事情。三个工具的效果和使用各不相同,使用方法可以通过官网文档去了解,三者的效果对比,后文会详细介绍。
二. tree-shaking 的原理

Tree-shaking 的本质是消除无用的 js 代码。无用代码消除在广泛存在于传统的编程语言编译器中,编译器可以判断出某些代码根本不影响输出,然后消除这些代码,这个称之为 DCE(dead code elimination)。
Tree-shaking 是 DCE 的一种新的实现,Javascript 同传统的编程语言不同的是,javascript 绝大多数情况需要通过网络进行加载,然后执行,加载的文件大小越小,整体执行时间更短,所以去除无用代码以减少文件体积,对 javascript 来说更有意义。
Tree-shaking 和传统的 DCE 的方法又不太一样,传统的 DCE 消灭不可能执行的代码,而 Tree-shaking 更关注于消除没有用到的代码。下面详细介绍一下 DCE 和 Tree-shaking。
(1)先来看一下 DCE 消除大法

Dead Code 一般具有以下几个特征
- 代码不会被执行,不可到达
- 代码执行的结果不会被用到
- 代码只会影响死变量(只写不读)
下面红框标示的代码就属于死码,满足以上特征
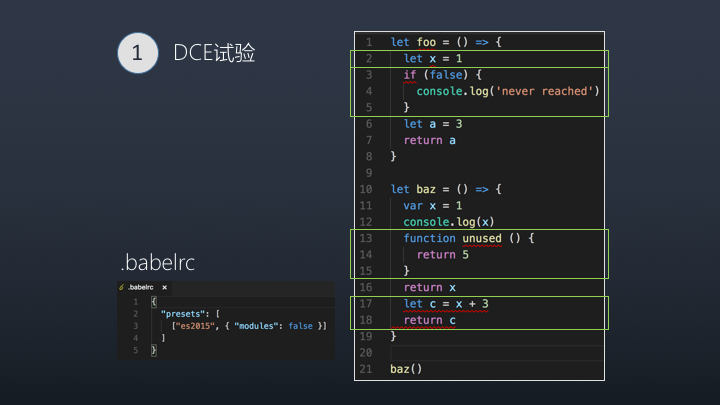
传统编译型的语言中,都是由编译器将 Dead Code 从 AST(抽象语法树)中删除,那 javascript 中是由谁做 DCE 呢?
首先肯定不是浏览器做 DCE,因为当我们的代码送到浏览器,那还谈什么消除无法执行的代码来优化呢,所以肯定是送到浏览器之前的步骤进行优化。
其实也不是上面提到的三个工具,rollup,webpack,cc 做的,而是著名的代码压缩优化工具 uglify,uglify 完成了 javascript 的 DCE,下面通过一个实验来验证一下。
以下所有的示例代码都能在 github 中找到
https://github.com/lin-xi/treeshaking/tree/master/rollup-webpack
分别用 rollup 和 webpack 将图 4 中的代码进行打包
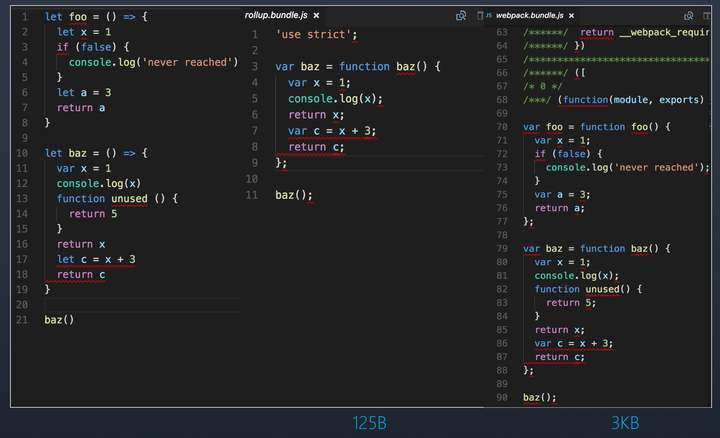
中间是 rollup 打包的结果,右边是 webpack 打包的结果
可以发现,rollup 将无用的代码 foo 函数和 unused 函数消除了,但是仍然保留了不会执行到的代码,而 webpack 完整的保留了所有的无用代码和不会执行到的代码。
分别用 rollup + uglify 和 webpack + uglify 将图 4 中的代码进行打包
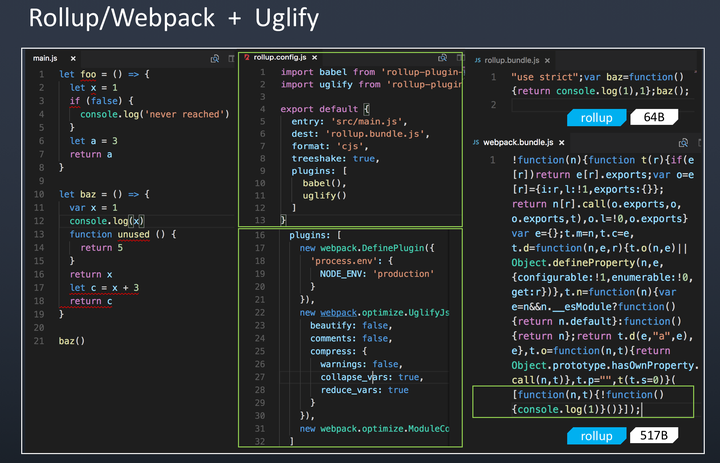
中间是配置文件,右侧是结果
可以看到右侧最终打包结果中都去除了无法执行到的代码,结果符合我们的预期。
(2) 再来看一下 Tree-shaking 消除大法
前面提到了 tree-shaking 更关注于无用模块的消除,消除那些引用了但并没有被使用的模块。
先思考一个问题,为什么 tree-shaking 是最近几年流行起来了?而前端模块化概念已经有很多年历史了,其实 tree-shaking 的消除原理是依赖于 ES6 的模块特性。

ES6 module 特点:
- 只能作为模块顶层的语句出现
- import 的模块名只能是字符串常量
- import binding 是 immutable 的
ES6 模块依赖关系是确定的,和运行时的状态无关,可以进行可靠的静态分析,这就是 tree-shaking 的基础。
所谓静态分析就是不执行代码,从字面量上对代码进行分析,ES6 之前的模块化,比如我们可以动态 require 一个模块,只有执行后才知道引用的什么模块,这个就不能通过静态分析去做优化。
这是 ES6 modules 在设计时的一个重要考量,也是为什么没有直接采用 CommonJS,正是基于这个基础上,才使得 tree-shaking 成为可能,这也是为什么 rollup 和 webpack 2 都要用 ES6 module syntax 才能 tree-shaking。
我们还是通过例子来详细了解一下
面向过程编程函数和面向对象编程是 javascript 最常用的编程模式和代码组织方式,从这两个方面来实验:
- 函数消除实验
- 类消除实验
先看下函数消除实验
utils 中 get 方法没有被使用到,我们期望的是 get 方法最终被消除。
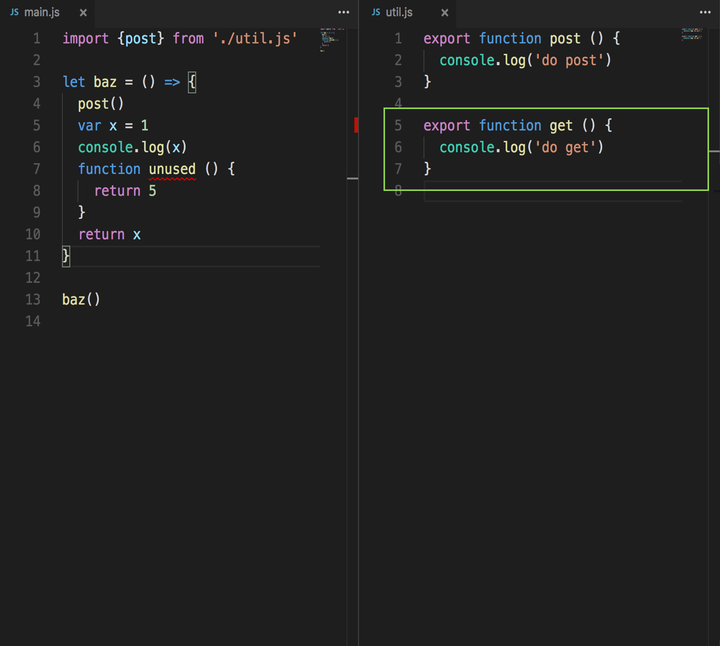
注意,uglify 目前不会跨文件去做 DCE,所以上面这种情况,uglify 是不能优化的。
先看看 rollup 的打包结果
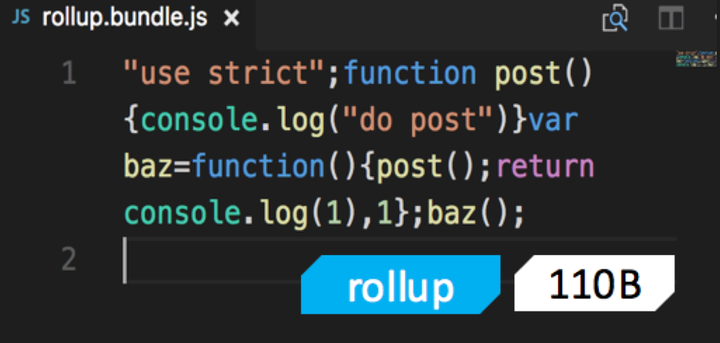
完全符合预期,最终结果中没有 get 方法
再看看 webpack 的结果
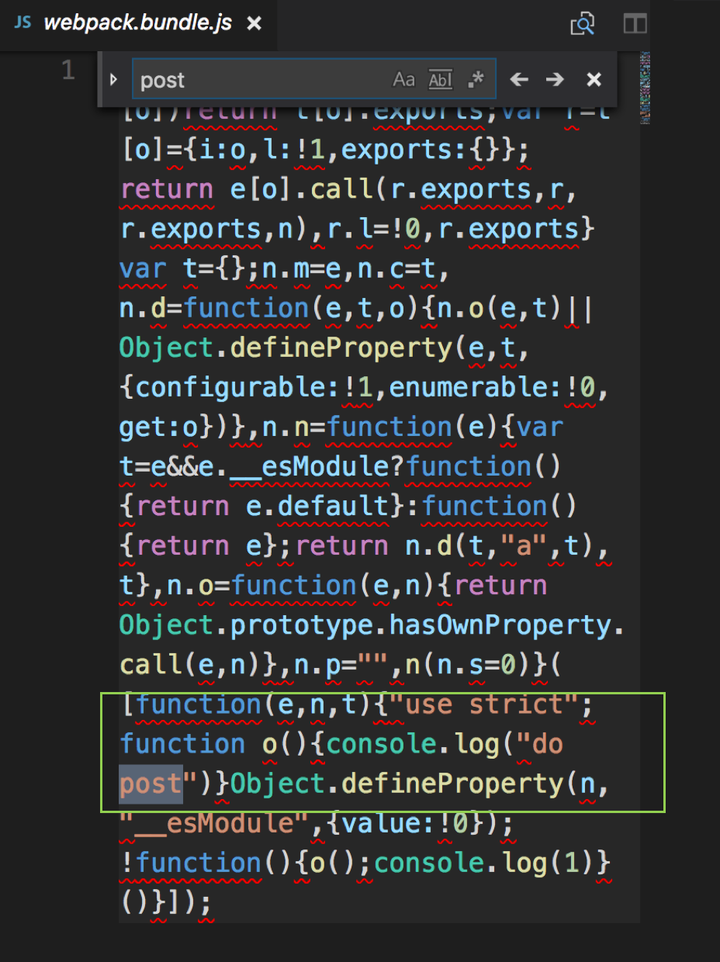
也符合预期,最终结果中没有 get 方法
可以看到 rollup 打包的结果比 webpack 更优化
函数消除实验中,rollup 和 webpack 都通过,符合预期
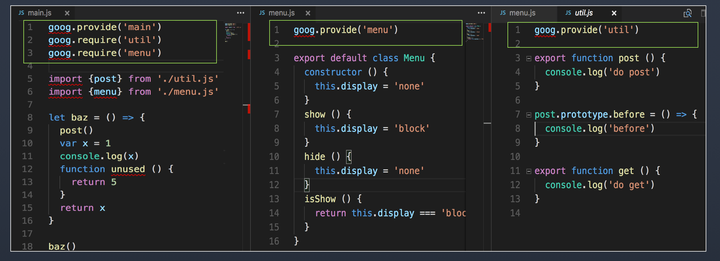
再来看下类消除实验
增加了对 menu.js 的引用,但其实代码中并没有用到 menu 的任何方法和变量,所以我们的期望是,最终代码中 menu.js 里的内容被消除
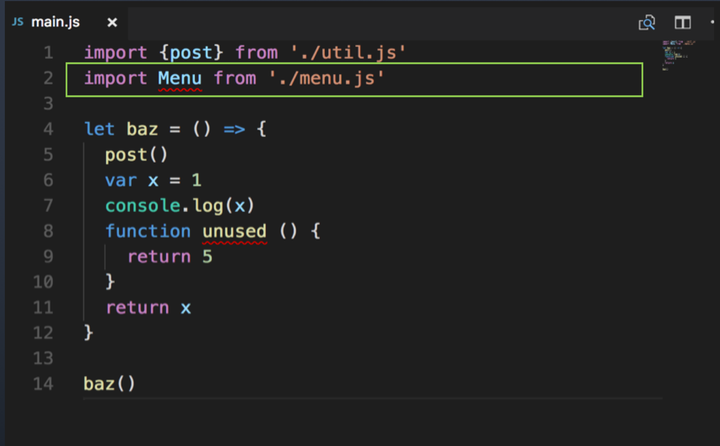
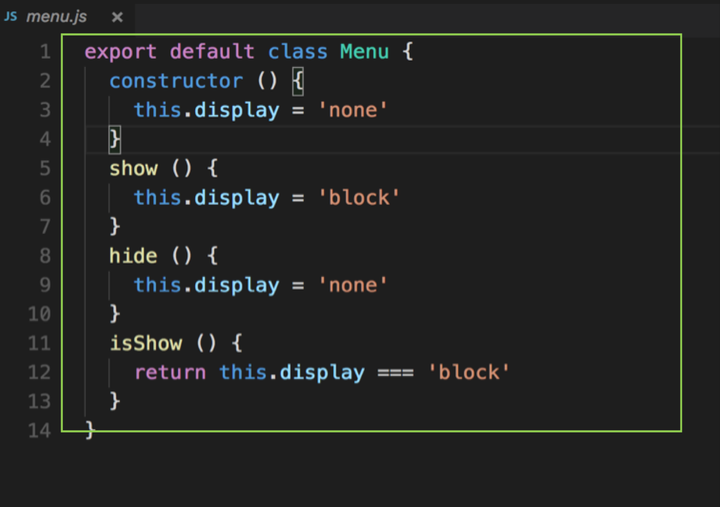
rollup 打包结果
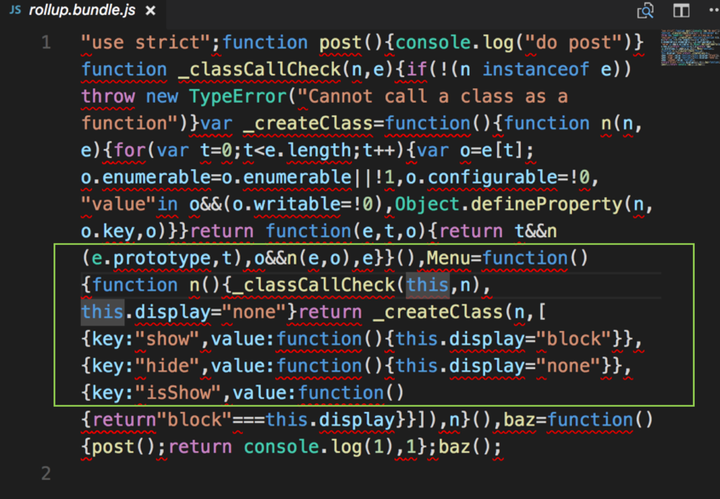
包中竟然包含了 menu.js 的全部代码
webpack 打包结果
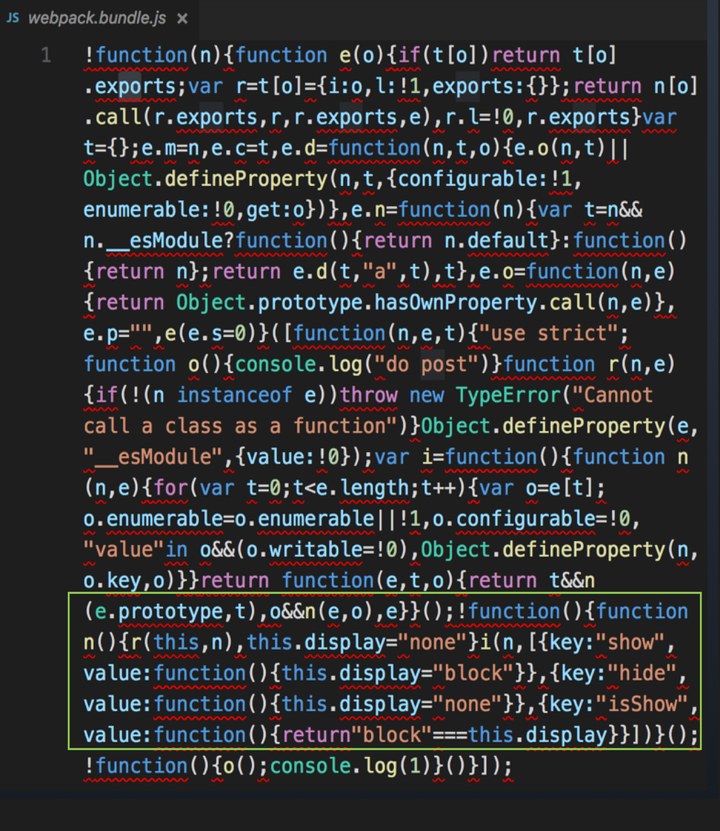
包中竟然也包含了 menu.js 的全部代码
类消除实验中,rollup,webpack 全军覆没,都没有达到预期

这跟我们想象的完全不一样啊?为什么呢?无用的类不能消除,这还能叫做 tree-shaking 吗?我当时一度怀疑自己的 demo 有问题,后来各种网上搜索,才明白 demo 没有错。
下面摘取了 rollup 核心贡献者的的一些回答:
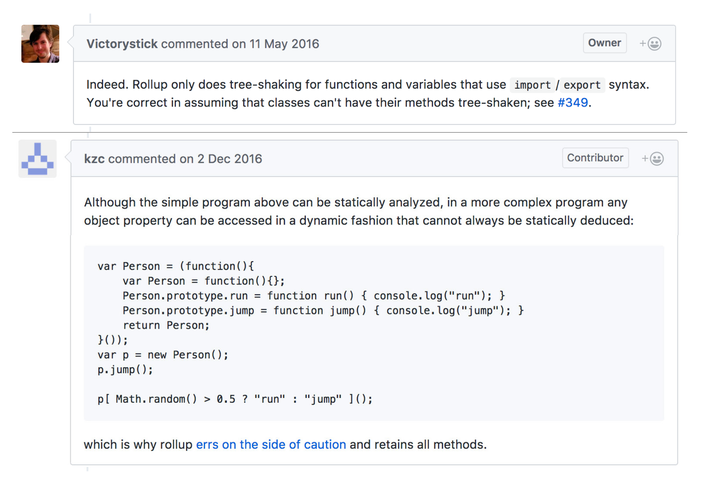
- rollup 只处理函数和顶层的 import/export 变量,不能把没用到的类的方法消除掉
- javascript 动态语言的特性使得静态分析比较困难
- 图 7 下部分的代码就是副作用的一个例子,如果静态分析的时候删除 run 或者 jump,程序运行时就可能报错,那就本末倒置了,我们的目的是优化,肯定不能影响执行
再举个例子说明下为什么不能消除 menu.js,比如下面这个场景
1 | function Menu() { |
如果删除 menu.js,那 Array 的扩展也会被删除,就会影响功能。那也许你会问,难道 rollup,webpack 不能区分是定义 Menu 的 proptotype 还是定义 Array 的 proptotype 吗?当然如果代码写成上面这种形式是可以区分的,如果我写成这样呢?
1 | function Menu() { |
这种代码,静态分析是分析不了的,就算能静态分析代码,想要正确完全的分析也比较困难。
更多关于副作用的讨论,可以看这个
https://github.com/rollup/rollup/issues/349

tree-shaking 对函数效果较好
函数的副作用相对较少,顶层函数相对来说更容易分析,加上 babel 默认都是”use strict”严格模式,减少顶层函数的动态访问的方式,也更容易分析
我们开始说的三个工具,rollup 和 webpack 表现不理想,那 closure compiler 又如何呢?
将示例中的代码用 cc 打包后得到的结果如下:
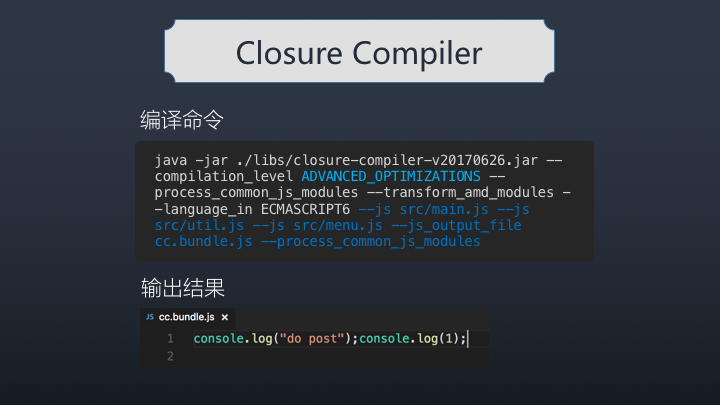
天啊,这不就是我们要的结果吗?完美消除所有无用代码的结果,输出的结果非常性感
closure compiler, tree-shaking 的结果完美!
可是不能高兴得太早,能得到这么完美结果是需要条件的,那就是 cc 的侵入式约束规范。必须在代码里添加这样的代码,看红线框标示的
google 定义一整套注解规范 Annotating JavaScript for the Closure Compiler,想更多了解的,可以去看下官网。
侵入式这个就让人很不爽,google Closure Compiler 是 java 写的,和我们基于 node 的各种构建库不可能兼容(不过目前好像已经有 nodejs 版 Closure Compiler),Closure Compiler 使用起来也比较麻烦,所以虽然效果很赞,但比较难以应用到项目中,迁移成本较大。
说了这么多,总结一下:
三大工具的 tree-shaking 对于无用代码,无用模块的消除,都是有限的,有条件的。closure compiler 是最好的,但与我们日常的基于 node 的开发流很难兼容。

tree-shaking 对 web 意义重大,是一个极致优化的理想世界,是前端进化的又一个终极理想。
理想是美好的,但目前还处在发展阶段,还比较困难,有各个方面的,甚至有目前看来无法解
决的问题,但还是应该相信新技术能带来更好的前端世界。
但优化是一种态度,不因小而不为,不因艰而不攻。
三、Tree-Shaking 的工作原理
Tree-shaking (树摇)最早是由 Rollup 实现,是一种采用删除不需要的额外代码的方式优化代码体积的技术,webpack2 借鉴了这个特性也增加了 tree-shaking 的功能。
tree-shaking 只能在静态 modules 下工作,在 ES6 之前我们使用 CommonJS 规范引入模块,具体采用 require()的方式动态引入模块,这个特性可以通过判断条件解决按需加载的优化问题,具体如下
1 | let module; |
但是 CommonJS 规范无法确定在实际运行前需要或者不需要某些模块,所以 CommonJS 不适合 tree-shaking 机制。
在 JavaScript 模块化方案中,只有 ES6 的模块方案:import()引入模块的方式采用静态导入,可以采用一次导入所有的依赖包再根据条件判断的方式,获取不需要的包,然后执行删除操作。
1 | import hello from "Hellow"; |
Tree-shaking 的实现原理
利用 ES6 模块特性:
- 只能作为模块顶层的语句出现
- import 的模块名只能是字符串常量
- import binding 是 immutable 的,引入的模块不能再进行修改
代码删除:
- uglify:判断程序流,判断变量是否被使用和引用,进而删除代码
实现原理可以简单的概况:
- ES6 Module 引入进行静态分析,故而编译的时候正确判断到底加载了那些模块
- 静态分析程序流,判断那些模块和变量未被使用或者引用,进而删除对应代码