1. 变量提升
通常 JS 引擎会在正式执行之前先进行一次预编译,在这个过程中,首先将变量声明及函数声明提升至当前作用域的顶端,然后进行接下来的处理。(注:当前流行的 JS 引擎大都对源码进行了编译,由于引擎的不同,编译形式也会有所差异,我们这里说的预编译和提升其实是抽象出来的、易于理解的概念)
下面的代码中,我们在函数中声明了一个变量,不过这个变量声明是在 if 语句块中:
1
2
3
4
5
6
7
8
| function hoistVariable() {
if (!foo) {
var foo = 5;
}
console.log(foo); // 5
}
hoistVariable();
|
运行代码,我们会发现 foo 的值是 5,初学者可能对此不甚理解,如果外层作用域也存在一个 foo 变量,就更加困惑了,该不会是打印外层作用域中的 foo 变量吧?答案是:不会,如果当前作用域中存在此变量声明,无论它在什么地方声明,引用此变量时就会在当前作用域中查找,不会去外层作用域了。
那么至于说打印结果,这要提到预编译机制了,经过一次预编译之后,上面的代码逻辑如下:
1
2
3
4
5
6
7
8
9
10
11
12
| // 预编译之后
function hoistVariable() {
var foo;
if (!foo) {
foo = 5;
}
console.log(foo); // 5
}
hoistVariable();
|
是的,引擎将变量声明提升到了函数顶部,初始值为 undefined,自然,if 语句块就会被执行,foo 变量赋值为 5,下面的打印也就是预期的结果了。
类似的,还有下面一个例子:
1
2
3
4
5
6
7
8
9
| var foo = 3;
function hoistVariable() {
var foo = foo || 5;
console.log(foo); // 5
}
hoistVariable();
|
foo || 5 这个表达式的结果是 5 而不是 3,虽然外层作用域有个 foo 变量,但函数内是不会去引用的,因为预编译之后的代码逻辑是这样的:
1
2
3
4
5
6
7
8
9
10
11
12
| var foo = 3;
// 预编译之后
function hoistVariable() {
var foo;
foo = foo || 5;
console.log(foo); // 5
}
hoistVariable();
|
如果当前作用域中声明了多个同名变量,那么根据我们的推断,它们的同一个标识符会被提升至作用域顶部,其他部分按顺序执行,比如下面的代码:
1
2
3
4
5
6
7
8
9
10
11
| function hoistVariable() {
var foo = 3;
{
var foo = 5;
}
console.log(foo); // 5
}
hoistVariable();
|
由于 JavaScript 没有块作用域,只有全局作用域和函数作用域,所以预编译之后的代码逻辑为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| // 预编译之后
function hoistVariable() {
var foo;
foo = 3;
{
foo = 5;
}
console.log(foo); // 5
}
hoistVariable();
|
2. 函数提升
相信大家对下面这段代码都不陌生,实际开发当中也很常见:
1
2
3
4
5
6
7
8
9
| function hoistFunction() {
foo(); // output: I am hoisted
function foo() {
console.log('I am hoisted');
}
}
hoistFunction();
|
为什么函数可以在声明之前就可以调用,并且跟变量声明不同的是,它还能得到正确的结果,其实引擎是把函数声明整个地提升到了当前作用域的顶部,预编译之后的代码逻辑如下:
1
2
3
4
5
6
7
8
9
10
| // 预编译之后
function hoistFunction() {
function foo() {
console.log('I am hoisted');
}
foo(); // output: I am hoisted
}
hoistFunction();
|
相似的,如果在同一个作用域中存在多个同名函数声明,后面出现的将会覆盖前面的函数声明:
1
2
3
4
5
6
7
8
9
10
11
12
13
| function hoistFunction() {
function foo() {
console.log(1);
}
foo(); // output: 2
function foo() {
console.log(2);
}
}
hoistFunction();
|
对于函数,除了使用上面的函数声明,更多时候,我们会使用函数表达式,下面是函数声明和函数表达式的对比:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| // 函数声明
function foo() {
console.log('function declaration');
}
// 匿名函数表达式
var foo = function() {
console.log('anonymous function expression');
};
// 具名函数表达式
var foo = function bar() {
console.log('named function expression');
};
|
可以看到,匿名函数表达式,其实是将一个不带名字的函数声明赋值给了一个变量,而具名函数表达式,则是带名字的函数赋值给一个变量,需要注意到是,这个函数名只能在此函数内部使用。我们也看到了,其实函数表达式可以通过变量访问,所以也存在变量提升同样的效果。
那么当函数声明遇到函数表达式时,会有什么样的结果呢,先看下面这段代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| function hoistFunction() {
foo(); // 2
var foo = function() {
console.log(1);
};
foo(); // 1
function foo() {
console.log(2);
}
foo(); // 1
}
hoistFunction();
|
运行后我们会发现,输出的结果依次是 2 1 1,为什么会有这样的结果呢?
因为 JavaScript 中的函数是一等公民,函数声明的优先级最高,会被提升至当前作用域最顶端,所以第一次调用时实际执行了下面定义的函数声明,然后第二次调用时,由于前面的函数表达式与之前的函数声明同名,故将其覆盖,以后的调用也将会打印同样的结果。上面的过程经过预编译之后,代码逻辑如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| // 预编译之后
function hoistFunction() {
var foo;
foo = function foo() {
console.log(2);
}
foo(); // 2
foo = function() {
console.log(1);
};
foo(); // 1
foo(); // 1
}
hoistFunction();
|
我们也不难理解,下面的函数和变量重名时,会如何执行:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| var foo = 3;
function hoistFunction() {
console.log(foo); // function foo() {}
foo = 5;
console.log(foo); // 5
function foo() {}
}
hoistFunction();
console.log(foo); // 3
|
我们可以看到,函数声明被提升至作用域最顶端,然后被赋值为 5,而外层的变量并没有被覆盖,经过预编译之后,上面代码的逻辑是这样的:
// 预编译之后
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| var foo = 3;
function hoistFunction() {
var foo;
foo = function foo() {};
console.log(foo); // function foo() {}
foo = 5;
console.log(foo); // 5
}
hoistFunction();
console.log(foo); // 3
|
所以,函数的优先权是最高的,它永远被提升至作用域最顶部,然后才是函数表达式和变量按顺序执行,这一点要牢记。
3. 为什么要进行提升
关于为什么进行变量提升和函数提升,这个问题一直没有明确的答案,不过最近读到 Dmitry Soshnikov 之前的一篇文章时,多少了解了一些,下面是 Dmitry Soshnikov 早些年的 twitter,他也对这个问题十分感兴趣:

然后 Jeremy Ashkenas 想让 Brendan Eich 聊聊这个话题:

最后,Brendan Eich 给出了答案:

大致的意思就是:由于第一代 JS 虚拟机中的抽象纰漏导致的,编译器将变量放到了栈槽内并编入索引,然后在(当前作用域的)入口处将变量名绑定到了栈槽内的变量。(注:这里提到的抽象是计算机术语,是对内部发生的更加复杂的事情的一种简化。)
然后,Dmitry Soshnikov 又提到了函数提升,他提到了相互递归(就是 A 函数内会调用到 B 函数,而 B 函数也会调用到 A 函数):

随后 Brendan Eich 很热心的又给出了答案:
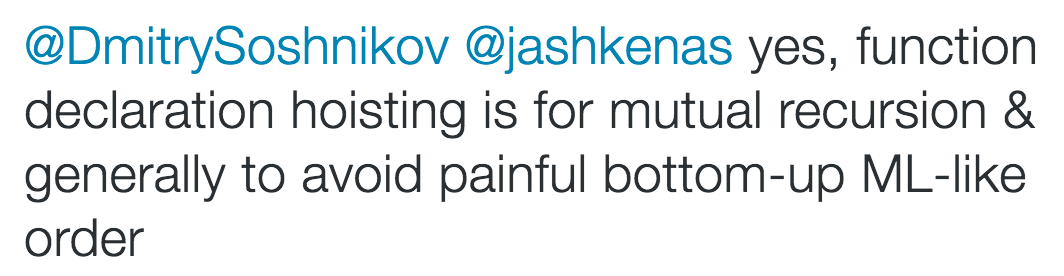
Brendan Eich 很确定的说,函数提升就是为了解决相互递归的问题,大体上可以解决像 ML 语言这样自下而上的顺序问题。
这里简单阐述一下相互递归,下面两个函数分别在自己的函数体内调用了对方:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| // 验证偶数
function isEven(n) {
if (n === 0) {
return true;
}
return isOdd(n - 1);
}
console.log(isEven(2)); // true
// 验证奇数
function isOdd(n) {
if (n === 0) {
return false;
}
return isEven(n - 1);
}
|
如果没有函数提升,而是按照自下而上的顺序,当 isEven 函数被调用时,isOdd 函数还未声明,所以当 isEven 内部无法调用 isOdd 函数。所以 Brendan Eich 设计了函数提升这一形式,将函数提升至当前作用域的顶部:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| // 验证偶数
function isEven(n) {
if (n === 0) {
return true;
}
return isOdd(n - 1);
}
// 验证奇数
function isOdd(n) {
if (n === 0) {
return false;
}
return isEven(n - 1);
}
console.log(isEven(2)); // true
|
这样一来,问题就迎刃而解了。
最后,Brendan Eich 还对变量提升和函数提升做了总结:

大概是说,变量提升是人为实现的问题,而函数提升在当初设计时是有目的的。
至此,关于变量提升和函数提升,相信大家已经明白其中的真相了。
4. 最佳实践
理解变量提升和函数提升可以使我们更了解这门语言,更好地驾驭它,但是在开发中,我们不应该使用这些技巧,而是要规范我们的代码,做到可读性和可维护性。
具体的做法是:无论变量还是函数,都必须先声明后使用。下面举了简单的例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| var name = 'Scott';
var sayHello = function(guest) {
console.log(name, 'says hello to', guest);
};
var i;
var guest;
var guests = ['John', 'Tom', 'Jack'];
for (i = 0; i < guests.length; i++) {
guest = guests[i];
// do something on guest
sayHello(guest);
}
|
如果对于新的项目,可以使用 let 替换 var,会变得更可靠,可维护性更高:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| let name = 'Scott';
let sayHello = function(guest) {
console.log(name, 'says hello to', guest);
};
let guests = ['John', 'Tom', 'Jack'];
for (let i = 0; i < guests.length; i++) {
let guest = guests[i];
// do something on guest
sayHello(guest);
}
|
值得一提的是,ES6 中的 class 声明也存在提升,不过它和 let、const 一样,被约束和限制了,其规定,如果再声明位置之前引用,则是不合法的,会抛出一个异常。
所以,无论是早期的代码,还是 ES6 中的代码,我们都需要遵循一点,先声明,后使用。