文章结构:
- React 中的虚拟 DOM 是什么?
- 虚拟 DOM 的简单实现(diff 算法)
- 虚拟 DOM 的内部工作原理
- React 中的虚拟 DOM 与 Vue 中的虚拟 DOM 比较
React 中的虚拟 DOM 是什么?
虽然 React 中的虚拟 DOM 很好用,但是这是一个无心插柳的结果。
React 的核心思想:一个 Component 拯救世界,忘掉烦恼,从此不再操心界面。
1. Virtual Dom 快,有两个前提
1.1 Javascript 很快
Chrome 刚出来的时候,在 Chrome 里跑 Javascript 非常快,给了其它浏览器很大压力。而现在经过几轮你追我赶,各主流浏览器的 Javascript 执行速度都很快了。
在 https://julialang.org/benchmarks/ 这个网站上,我们可以看到,JavaScript 语言已经非常快了,和 C 就是几倍的关系,和 java 在同一个量级。所以说,单纯的 JavaScript 还是很快的。
1.2 Dom 很慢
当创建一个元素比如 div,有以下几项内容需要实现: HTML element、Element、GlobalEventHandler。简单的说,就是插入一个 Dom 元素的时候,这个元素上本身或者继承很多属性如 width、height、offsetHeight、style、title,另外还需要注册这个元素的诸多方法,比如 onfocus、onclick 等等。 这还只是一个元素,如果元素比较多的时候,还涉及到嵌套,那么元素的属性和方法等等就会很多,效率很低。
比如,我们在一个空白网页的 body 中添加一个 div 元素,如下所示:

这个元素会挂载默认的 styles、得到这个元素的 computed 属性、注册相应的 Event Listener、DOM Breakpoints 以及大量的 properties,这些属性、方法的注册肯定是需要耗费大量时间的。
尤其是在 js 操作 DOM 的过程中,不仅有 dom 本身的繁重,js 的操作也需要浪费时间,我们认为 js 和 DOM 之间有一座桥,如果你频繁的在桥两边走动,显然效率是很低的,如果你的 JavaScript 操作 DOM 的方式还非常不合理,那么显然就会更糟糕了。
而 React 的虚拟 DOM 就是解决这个问题的! 虽然它解决不了 DOM 自身的繁重,但是虚拟 DOM 可以对 JavaScript 操作 DOM 这一部分内容进行优化。
比如说,现在你的 list 是这样:
1 | <ul> |
你希望把它变成下面这样:
1 | <ul> |
通常的操作是什么?
先把 0, 1,2,3 这些 Element 删掉,然后加几个新的 Element 6,7,8,9,10 进去,这里面就有 4 次 Element 删除,5 次 Element 添加。共计 9 次 DOM 操作。
那 React 的虚拟 DOM 可以怎么做呢?
而 React 会把这两个做一下 Diff,然后发现其实不用删除 0,1,2,3,而是可以直接改 innerHTML,然后只需要添加一个 Element(10)就行了,这样就是 4 次 innerHTML 操作加 1 个 Element 添加。共计 5 次操作,这样效率的提升是非常可观的。
2、 关于 React
2.1 接口和设计
在 React 的设计中,是完全不需要你来操作 DOM 的。我们也可以认为,在 React 中根本就没有 DOM 这个概念,有的只是 Component。
当你写好一个 Component 以后,Component 会完全负责 UI,你不需要也不应该去也不能够指挥 Component 怎么显示,你只能告诉它你想要显示一个香蕉还是两个梨。
隔离 DOM 并不仅仅是因为 DOM 慢,而也是为了把界面和业务完全隔离,操作数据的只关心数据,操作界面的只关心界面。比如在 websocket 聊天室的创建房间时,我们可以首先把 Component 写好,然后当获取到数据的时候,只要把数据放在 redux 中就好,然后 Component 就自动把房间添加到页面中去,而不是你先拿到数据,然后使用 js 操作 DOM 把数据显示在页面上。
即我提供一个 Component,然后你只管给我数据,界面的事情完全不用你操心,我保证会把界面变成你想要的样子。所以说 React 的着力点就在于 View 层,即 React 专注于 View 层。你可以把一个 React 的 Component 想象成一个 Pure Function,只要你给的数据是[1, 2, 3],我保证显示的是[1, 2, 3]。没有什么删除一个 Element,添加一个 Element 这样的事情。NO。你要我显示什么就给我一个完整的列表。
另外,Flux 虽然说的是单向的 Data Flow(redux 也是),但是实际上就是单向的 Observer,Store->View->Action->Store(箭头是数据流向,实现上可以理解为 View 监听 Store,View 直接 trigger action,然后 Store 监听 Action)。
2.2 实现
那么 react 如何实现呢? 最简单的方法就是当数据变化时,我直接把原先的 DOM 卸载,然后把最新数据的 DOM 替换上去。 但是,虚拟 DOM 哪去了? 这样做的效率显然是极低的。
所以虚拟 DOM 就来救场了。
那么虚拟 DOM 和 DOM 之间的关系是什么呢?
首先,Virtual DOM 并没有完全实现 DOM,即虚拟 DOM 和真正地 DOM 是不一样的,Virtual DOM 最主要的还是保留了 Element 之间的层次关系和一些基本属性。因为真实 DOM 实在是太复杂,一个空的 Element 都复杂得能让你崩溃,并且几乎所有内容我根本不关心好吗。所以 Virtual DOM 里每一个 Element 实际上只有几个属性,即最重要的,最为有用的,并且没有那么多乱七八糟的引用,比如一些注册的属性和函数啊,这些都是默认的,创建虚拟 DOM 进行 diff 的过程中大家都一致,是不需要进行比对的。所以哪怕是直接把 Virtual DOM 删了,根据新传进来的数据重新创建一个新的 Virtual DOM 出来都非常非常非常快。(每一个 component 的 render 函数就是在做这个事情,给新的 virtual dom 提供 input)。
所以,引入了 Virtual DOM 之后,React 是这么干的:你给我一个数据,我根据这个数据生成一个全新的 Virtual DOM,然后跟我上一次生成的 Virtual DOM 去 diff,得到一个 Patch,然后把这个 Patch 打到浏览器的 DOM 上去。完事。并且这里的 patch 显然不是完整的虚拟 DOM,而是新的虚拟 DOM 和上一次的虚拟 DOM 经过 diff 后的差异化的部分。
假设在任意时候有,VirtualDom1 == DOM1 (组织结构相同, 显然虚拟 DOM 和真实 DOM 是不可能完全相等的,这里的==是 js 中非完全相等)。当有新数据来的时候,我生成 VirtualDom2,然后去和 VirtualDom1 做 diff,得到一个 Patch(差异化的结果)。然后将这个 Patch 去应用到 DOM1 上,得到 DOM2。如果一切正常,那么有 VirtualDom2 == DOM2(同样是结构上的相等)。
这里你可以做一些小实验,去破坏 VirtualDom1 == DOM1 这个假设(手动在 DOM 里删除一些 Element,这时候 VirtualDom 里的 Element 没有被删除,所以两边不一样了)。
然后给新的数据,你会发现生成的界面就不是你想要的那个界面了。
最后,回到为什么 Virtual Dom 快这个问题上。
其实是由于每次生成 virtual dom 很快,diff 生成 patch 也比较快,而在对 DOM 进行 patch 的时候,虽然 DOM 的变更比较慢,但是 React 能够根据 Patch 的内容,优化一部分 DOM 操作,比如之前的那个例子。
重点就在最后,哪怕是我生成了 virtual dom(需要耗费时间),哪怕是我跑了 diff(还需要花时间),但是我根据 patch 简化了那些 DOM 操作省下来的时间依然很可观(这个就是时间差的问题了,即节省下来的时间 > 生成 virtual dom 的时间 + diff 时间)。所以总体上来说,还是比较快。
简单发散一下思路,如果哪一天,DOM 本身的操作已经非常非常非常快了,并且我们手动对于 DOM 的操作都是精心设计优化过后的,那么加上了 VirtualDom 还会快吗?
当然不行了,毕竟你多做了这么多额外的工作。
但是那一天会来到吗?
诶,大不了到时候不用Virtual DOM。
注: 此部分内容整理自:https://www.zhihu.com/question/29504639/answer/44680878
虚拟 DOM 的简单实现(diff 算法)
目录
- 1 前言
- 2 对前端应用状态管理思考
- 3 Virtual DOM 算法
- 4 算法实现
- 4.1 步骤一:用 JS 对象模拟 DOM 树
- 4.2 步骤二:比较两棵虚拟 DOM 树的差异
- 4.3 步骤三:把差异应用到真正的 DOM 树上
- 5 结语
前言
在上面一部分中,我们已经简单介绍了虚拟 DOM 的答题思路和好处,这里我们将通过自己写一个虚拟 DOM 来加深对其的理解,有一些自己的思考。
对前端应用状态管理思考
维护状态,更新视图。
虚拟 DOM 算法
DOM 是很慢的,如果我们创建一个简单的 div,然后把他的所有的属性都打印出来,你会看到:
1 | var div = document.createElement('div'), |

可以看到,这些属性还是非常惊人的,包括样式的修饰特性、一般的特性、方法等等,如果我们打印出其长度,可以得到惊人的 227 个。
而这仅仅是一层,真正的 DOM 元素是非常庞大的,这是因为标准就是这么设计的,而且操作他们的时候你要小心翼翼,轻微的触碰就有可能导致页面发生重排,这是杀死性能的罪魁祸首。
而相对于 DOM 对象,原生的 JavaScript 对象处理起来更快,而且更简单,DOM 树上的结构信息我们都可以使用 JavaScript 对象很容易的表示出来。
1 | var element = { |
如上所示,对于一个元素,我们只需要一个 JavaScript 对象就可以很容易的表示出来,这个对象中有三个属性:
- tagName: 用来表示这个元素的标签名。
- props: 用来表示这元素所包含的属性。
- children: 用来表示这元素的 children。
而上面的这个对象使用 HTML 表示就是:
1 | <ul id='list'> |
OK! 既然原来的 DOM 信息可以使用 JavaScript 来表示,那么反过来,我们就可以用这个 JavaScript 对象来构建一个真正的 DOM 树。
所以之前所说的状态变更的时候会重新构建这个 JavaScript 对象,然后呢,用新渲染的对象和旧的对象去对比, 记录两棵树的差异,记录下来的就是我们需要改变的地方。 这就是所谓的虚拟 DOM,包括下面的几个步骤:
- 用 JavaScript 对象来表示 DOM 树的结构; 然后用这个树构建一个真正的 DOM 树,插入到文档中。
- 当状态变更的时候,重新构造一个新的对象树,然后用这个新的树和旧的树作对比,记录两个树的差异。
- 把 2 所记录的差异应用在步骤一所构建的真正的 DOM 树上,视图就更新了。
Virtual DOM 的本质就是在 JS 和 DOM 之间做一个缓存,可以类比 CPU 和硬盘,既然硬盘这么慢,我们就也在他们之间添加一个缓存; 既然 DOM 这么慢,我们就可以在 JS 和 DOM 之间添加一个缓存。 CPU(JS)只操作内存(虚拟 DOM),最后的时候在把变更写入硬盘(DOM)。
算法实现
1、 用 JavaScript 对象模拟 DOM 树
用 JavaScript 对象来模拟一个 DOM 节点并不难,你只需要记录他的节点类型(tagName)、属性(props)、子节点(children)。
element.js
1 | function Element(tagName, props, children) { |
通过这个构造函数,我们就可以传入标签名、属性以及子节点了,tagName 可以在我们 render 的时候直接根据它来创建真实的元素,这里的 props 使用一个对象传入,可以方便我们遍历。
基本使用方法如下:
1 | var el = require('./element'); |
然而,现在的 ul 只是 JavaScript 表示的一个 DOM 结构,页面上并没有这个结构,所有我们可以根据 ul 构建一个真正的<ul>:
1 | Element.prototype.render = function () { |
所以,render 方法会根据 tagName 构建一个真正的 DOM 节点,然后设置这个节点的属性,最后递归的把自己的子节点也构建起来,所以只需要调用 ul 的 render 方法,通过 document.body.appendChild 就可以挂载到真实的页面上了。
1 | <!DOCTYPE html> |
上面的这段代码,就可以渲染出下面的结果了:

2、比较两颗虚拟 DOM 树的差异
比较两颗 DOM 树的差异是 Virtual DOM 算法中最为核心的部分,这也就是所谓的 Virtual DOM 的 diff 算法。 两个树的完全的 diff 算法是一个时间复杂度为 O(n3) 的问题。 但是在前端中,你会很少跨层地移动 DOM 元素,所以真实的 DOM 算法会对同一个层级的元素进行对比。
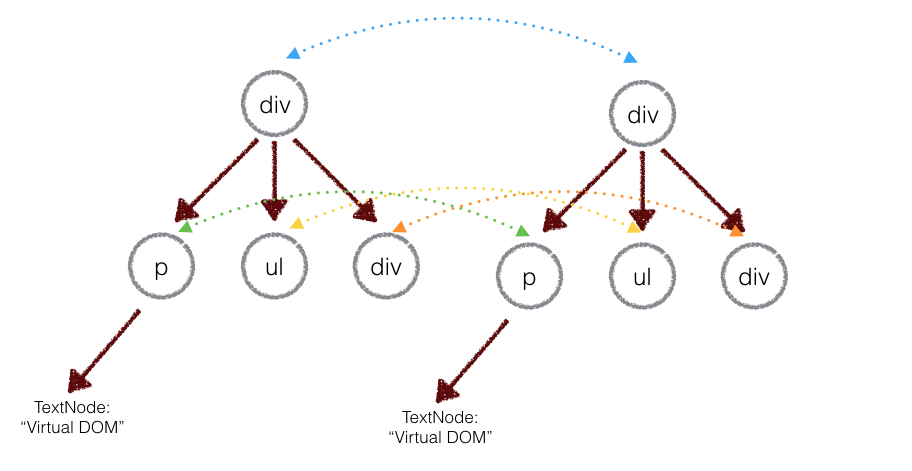
上图中,div 只会和同一层级的 div 对比,第二层级的只会和第二层级对比。 这样算法复杂度就可以达到 O(n)。
(1)深度遍历优先,记录差异
在实际的代码中,会对新旧两棵树进行一个深度优先的遍历,这样每一个节点就会有一个唯一的标记:
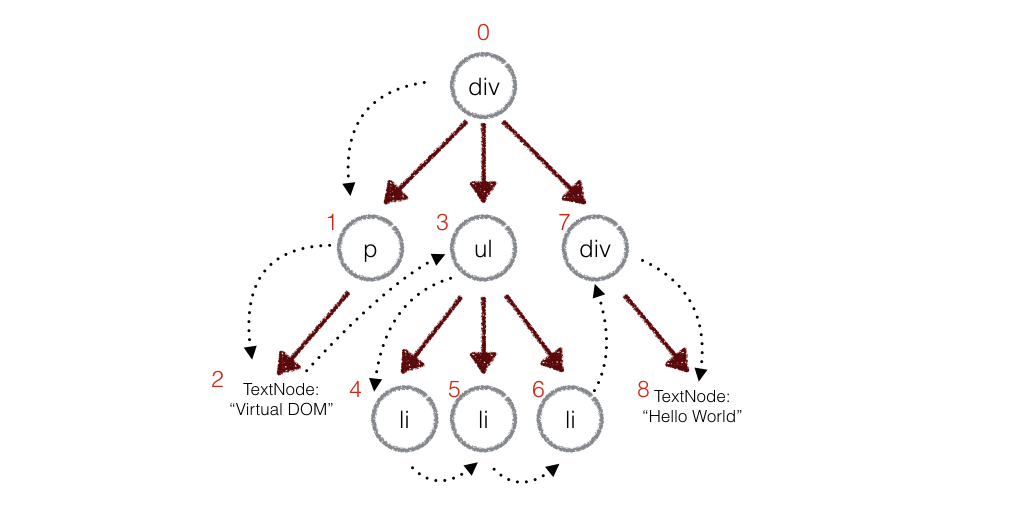
上面的这个遍历过程就是深度优先,即深度完全完成之后,再转移位置。 在深度优先遍历的时候,每遍历到一个节点就把该节点和新的树进行对比,如果有差异的话就记录到一个对象里面。
1 | // diff函数,对比两颗树 |
例如,上面的 div 和新的 div 有差异,当前的标记是 0, 那么我们可以使用数组来存储新旧节点的不同:
1 | patches[0] = [{difference}, {difference}, ...] |
同理使用 patches[1]来记录 p,使用 patches[3]来记录 ul,以此类推。
(2)差异类型
上面说的节点的差异指的是什么呢? 对 DOM 操作可能会:
- 替换原来的节点,如把上面的 div 换成了 section。
- 移动、删除、新增子节点, 例如上面 div 的子节点,把 p 和 ul 顺序互换。
- 修改了节点的属性。
- 对于文本节点,文本内容可能会改变。 例如修改上面的文本内容 2 内容为 Virtual DOM2.
所以,我们可以定义下面的几种类型:
1 | var REPLACE = 0; |
对于节点替换,很简单,判断新旧节点的 tagName 是不是一样的,如果不一样的说明需要替换掉。 如 div 换成了 section,就记录下:
1 | patches[0] = [{ |
除此之外,如果给 div 新增了属性 id 为 container,就记录下:
1 | pathches[0] = [ |
如果是文本节点发生了变化,那么就记录下:
1 | pathches[2] = [ |
那么如果我们把 div 的子节点重新排序下了呢? 比如 p、ul、div 的顺序换成了 div、p、ul,那么这个该怎么对比呢? 如果按照同级进行顺序对比的话,他们就会被替换掉,如 p 和 div 的 tagName 不同,p 就会被 div 所代替,最终,三个节点就都会被替换,这样 DOM 开销就会非常大,而实际上是不需要替换节点的,只需要移动就可以了, 我们只需要知道怎么去移动。这里牵扯到了两个列表的对比算法,如下。
(3)列表对比算法
假设现在可以用英文字母唯一地标识每一个子节点:
旧的节点顺序:
1 | a b c d e f g h i |
现在对节点进行了删除、插入、移动的操作。新增 j 节点,删除 e 节点,移动 h 节点:
新的节点顺序:
1 | a b c h d f g i j |
现在知道了新旧的顺序,求最小的插入、删除操作(移动可以看成是删除和插入操作的结合)。这个问题抽象出来其实是字符串的最小编辑距离问题(Edition Distance),最常见的解决算法是 Levenshtein Distance,通过动态规划求解,时间复杂度为 O(M * N)。但是我们并不需要真的达到最小的操作,我们只需要优化一些比较常见的移动情况,牺牲一定 DOM 操作,让算法时间复杂度达到线性的(O(max(M, N))。具体算法细节比较多,这里不累述,有兴趣可以参考代码。
我们能够获取到某个父节点的子节点的操作,就可以记录下来:
1 | patches[0] = [{ |
但是要注意的是,因为 tagName 是可重复的,不能用这个来进行对比。所以需要给子节点加上唯一标识 key,列表对比的时候,使用 key 进行对比,这样才能复用老的 DOM 树上的节点。
这样,我们就可以通过深度优先遍历两棵树,每层的节点进行对比,记录下每个节点的差异了。完整 diff 算法代码可见 diff.js。
3、把差异引用到真正的 DOM 树上
因为步骤一所构建的 JavaScript 对象树和 render 出来真正的 DOM 树的信息、结构是一样的。所以我们可以对那棵 DOM 树也进行深度优先的遍历,遍历的时候从步骤二生成的 patches 对象中找出当前遍历的节点差异,然后进行 DOM 操作。
1 | function patch (node, patches) { |
applyPatches,根据不同类型的差异对当前节点进行 DOM 操作:
1 | function applyPatches (node, currentPatches) { |
5、结语
virtual DOM 算法主要实现上面步骤的三个函数: element、diff、patch,然后就可以实际的进行使用了。
1 | // 1. 构建虚拟DOM |
当然这是非常粗糙的实践,实际中还需要处理事件监听等;生成虚拟 DOM 的时候也可以加入 JSX 语法。这些事情都做了的话,就可以构造一个简单的 ReactJS 了。